Artifact Removal in C# with OpenCV
Recently I solved a computer-vision problem that came up in a project which I found interesting and wanted to share. More specifically it boiled down to a problem of artifact removal and it goes like this:
The Problem
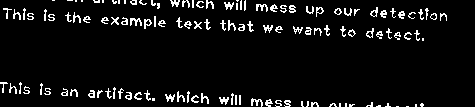
Given the following image which is a cutout of a scan of a sheet of paper:

There are one or more lines of text that are interested in and we want to use an OCR (Optical Character Recognition) Engine on it to retrieve the text.
Now the problem is, that there are some artifacts in addition to the text that we are interested in. If we feed the whole cutout into the OCR engine we get back the text we are looking for, but we also get the results of running the OCR on the artifacts as well.
So the process currently looks like that:

Of course it’s possible to process the text after having run the OCR and that even makes perfect sense incase the structure of the text that you are looking for is well known, like e.g. a telephone number in a specific format. In that case you can simply post process the output of the OCR with a regex or parse the text yourself.
In that case you can extend your pipeline to look like that:

But that’s not always the case. It could be that the information upon which you can decide what is an artifact and what is the content is in the relative positions they take up in the image.
If that’s the case you need to remove the artifacts before the OCR step, else you lose the information on which you would base this decision.
So the process will look like:

But enough with the abstract, let’s take another look at the example:
Here we are interested in the middle line, the one reading “This is the example text that we want to detect.”.
Notice the additional lines of text at the top and the bottom, which we don’t want. Additionally the scan itself is often rotated a few degrees, as shown in the example.
So the question is: How do we get only the relevant portions from the image?
Note: As you might have guessed, this specific example is made up by me, because the original images contain confidential information that I am not allowed to share.
A False Start
My first attempt to solve the problem was thwarted by the rotation of the image. I tried to find a Region of interest (a rectangle that is smaller than the image and contains only the relevant text) but this approach failed when it came to rotated images:

As you can see, I’ve got the option to either cut off the top of “This is…” or I still had some artifacts from the end of the top line remaining.
A better Solution
On my next attempt, I looked at the image and tried to distill the rules by which to decide if something is an artifact or not.
In this project, the artifacts where more or less continous artifacts that either touched the top or bottom of the image.
The strategy that I came up with is as follows:
- Load the image
- Get the positions of all objects
- Find all objects that are near the top or bottom border
- Find the sentences by recursively finding all objects that are next to previously found objects
- Remove all artifacts from the image
0. Load the image
Before we can start manipulating the image, we need to load it and make sure it’s a grayscale image.
var input = File.ReadAllBytes(file);
using (var mat = Mat.FromImageData(input))
using (var grey = mat.CvtColor(ColorConversionCodes.BGR2GRAY))1. Get the positions of all objects
Finding the positions of the objects is really easy with OpenCV. All you need to do is call FindContours().
Well almost. The thing is that FindContours() works on binary images (which is a fancy word for black and white images), where everything that is not a zero (perfect black), is treated like an object. That means before you can call Cv2.FindContours() you first need to do a black/white conversion and invert the result.
The process of generating a binary image is called thresholding, because pixels are tested against a specified threshold and then (usually) either changed to black or white. OpenCV supports thresholding with a couple of different methods, for example Cv2.Threshold.
Note:
For noisy real word data (scanned images!) you might want to use the fancier Cv2.AdaptiveThreshold for better results like so:
using (var thresholded = new Mat())
{
Cv2.AdaptiveThreshold(grey, thresholded, 255, AdaptiveThresholdTypes.GaussianC, ThresholdTypes.BinaryInv, 15, 7);
...Given the input image, thresholding with inversion produces the following result:
2. Find all objects near the borders
Cv2.FindContours() allows us to retrieve the bounding boxes of all contours in the image. This makes identifying the objects near the top and bottom border trivially easy.
Now that we can find all letters that are near the border, the question is: How can we find the letters next to those at the border? And the ones close to them and so on? Or to put it in another way: How can we find all sentences that are close to border.
3. Find the sentences
Turns out, that’s not an easy problem to solve! The first thing that came to my mind was naively computing the distance between all points of the bounding boxes of the objects. But this has a couple of problems, for example you need multiple passes because you need to repeat the proximity test for all contours after a new contour is found to be in close proximity. But what’s even worse is, that it’s wrong for contours when an edge is closer to another contour than a point of it’s bounding box.
After noticing that this problem is way more complicated than I previously thought, I backtracked a little and found a nice solution by visually joining the objects before calling Cv2.FindContours().
This operation is called dilation and I am using the Cv2.MorphologyEx method for that. One of the parameters of that method is a structuring element. The structuring element is a fancy name for the width and height of a rectangle that is used to extend the existing objects.
int dilateX = 15, dilateY = 3;
using (var dilateKernel = Cv2.GetStructuringElement(MorphShapes.Ellipse, new Size(dilateX, dilateY)))
using (var morphed = new Mat())
{
Cv2.MorphologyEx(thresholded, morphed, MorphTypes.Dilate, dilateKernel);
...The following image shows the result of the dilation:

When we now call Cv2.FindContours() instead of getting a contour for each letter, we only get 3 contours - one for each sentence - which can be done with the following C# Code:
Mat[] contours; var hierarchy = new Mat();
Cv2.FindContours(morphed, out contours, hierarchy, RetrievalModes.External, ContourApproximationModes.ApproxSimple);Note: Here I am passing RetrievalModes.External so that only the outermost contours are returned.
The following image visualizes the contours drawn over the input image:

Now we can easily find all contours whose bounding box touches the top or bottom border.
var imageHeight = mat.Height;
var yThreshold = 2;
var items = contours
.Select(c => new { Contour = c, BoundingBox = c.BoundingRect() })
.ToArray();
/* filter all contours that are near the top border or bottom border */
var filteredTopBottom = items
.Where(i => i.BoundingBox.Top <= yThreshold ||
(imageHeight - i.BoundingBox.Bottom) <= yThreshold)
.ToArray();4. Remove all artifacts
To remove the artifacts we simply draw over their contours and by doing so remove them from the image.
This can be done with the Cv2.DrawContours() method:
Cv2.DrawContours(fixedImage, filteredContours, -1, new Scalar(255, 255, 255), Cv2.FILLED);And finally we are left with the clean, final image that we can pass on to the OCR engine:

Summary
In this article I tried to show how OpenCV can be used from C# to solve real-world computer vision problems.
Because the difficult part was figuring out how to tackle the problem at hand (and not necessarily the code itself), I tried to document my thought process including the dead ends.
If you want, you can find the complete example code here.
References
-
Artifact Removal Github Repo (https://github.com/8/ArtifactRemoval)
-
OpenCV Documentation (https://docs.opencv.org/3.0-beta/modules/refman.html)
-
Optical Character Recognition (https://en.wikipedia.org/wiki/Optical_character_recognition)
-
Thresholding (https://en.wikipedia.org/wiki/Thresholding_(image_processing))
-
Dilation (https://en.wikipedia.org/wiki/Dilation_(morphology)